
Object placement
Cormac Hogan has a nice post on the nature of VSAN from an "Objects & Components" perspective, Rawlinson Rivera describes witness creation & placement, and Duncan Epping teaches the user how to see the placement of objects in VSAN.
Based on these (and many other articles written by them and other authors—check out Duncan's compendium of VSAN links) I thought I had a pretty good idea of how a VM would be laid out on a VSAN datastore.
Turns out, I was wrong...
Default use case
Take a VM with a single VMDK and put it on a VSAN datastore with no storage policy, and you get the default configuration of Number of Failures to Tolerate (nFT) = 1 and Number of Disk Stripes per Object (nSO) = 1. You'd expect to see the disk mirrored between two hosts, with a third host acting as witness:
 |
| Image shamelessly copied from Duncan |
If you drill down into the object information on the Web Client, it bears out what you'd expect:
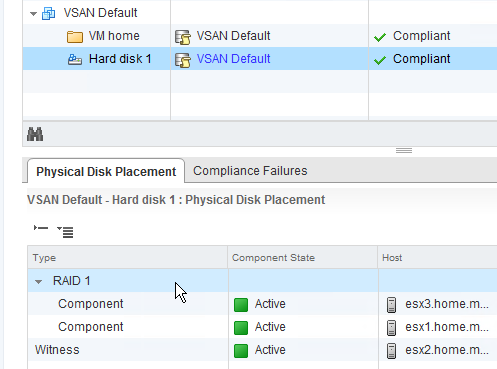
Multi-stripe use case
The purpose of the "Number of Disk Stripes per Object" policy is to leverage additional disks in a host to provide more performance. The help text from the nSO policy is as follows:
The number of HDDs across which each replica of a storage object is striped. A value higher than 1 may result in better performance (for e.g. when flash read cache misses need to get services from HDD), but also results in higher use of system resources. Default value 1, Maximum value: 12.In practice, adding additional stripes results in VSAN adding a new "RAID 0" layer in the leaf objects hierarchy under the "RAID 1" layer. That first level is the per-host distribution of objects needed to meet the nFT policy rule; this second layer represents the per-host distribution of objects necessary to meet the nSO policy rule.

As you can see from the diagram, the stripes for a single replica aren't necessarily written to the same host. Somehow, I'd gotten the impression that a replica had a 1:1 relationship with a host, which isn't the way it's run in practice.
I'd also been misreading the details in the web client for the distribution of the components; when all your disks have a display name that only varies in the least-significant places of the "naa" identifier, it's easy to get confused. To get around that, I renamed all my devices to reflect the host.slot and type so I could see where everything landed at a glance:

As this screencap shows, the VM's disk is a 4-part stripe, split among all three of my hosts. One host (esx2) has all four components, so the other hosts need enough "secondary" witnesses to balance it out (three for esx3 because it hold one data component, one for host esx1 because it holds three data components). There's also a "tiebreaker" witness (on esx1) because the sum of the data components and secondary witnesses is an even number.
The other disks show similar distribution, but the details of disk utilization is not the same. The only thing I've found to be fairly consistent in my testing is that one host will always get an entire replica, while the other two hosts share components for the other replica; this occurs for all policies with nSO>1. If you have more than 3 hosts, your results will likely be different.
You have made some decent points there. I looked on the internet for more info about the issue and found most people online grocery app in dubai will go along with your views on this website.
ReplyDelete